Scraping and Analyzing Elon Musk's Tweets for NLP Projects
Written on
Introduction to Data Collection
The vast expanse of data on the internet expands at a remarkable rate every year. A significant portion of this data falls under the category of "unstructured data," which encompasses various formats such as natural language text, images, videos, and documents that do not conform to a set data structure. This type of data has become crucial in driving many recent advancements in machine learning and artificial intelligence.
How to Acquire Data for ML Projects
If you're wondering how to obtain the data necessary for building your own machine learning algorithms or products, you're not alone. This article aims to guide you through the process of scraping and labeling your own data specifically for sentiment analysis tasks. By the end of this guide, you'll be equipped to replicate and customize the process to fit your needs, as we will provide the code required for each step.
Our Project: Scraping Tweets and Human Evaluation
The primary objective of our project was to assemble a dataset suitable for training a sentiment analysis model. We chose to focus on tweets since they are succinct and directly relevant to our use case. Moreover, we centered our analysis on the tweets of a single, highly recognizable figure: Elon Musk. This approach allows for the creation of a specialized dataset that can enhance an existing general sentiment model to cater to an "Elon niche."
We initiated the project by scraping numerous tweets from Elon Musk and subsequently labeling the sentiments conveyed in those tweets.
Gathering Data with Bright Data
To scrape the tweets, we utilized the Bright Data API, which is versatile enough to handle various data types beyond what we needed. This tool offers advantages over traditional scraping methods, such as mitigating issues related to IP address changes and blocked requests. As a result, the scraping process is more scalable and manageable.
We simply configured the Bright Data Collector and specified the website to scrape. The setup was automatic, and we quickly obtained around thirty of Elon Musk's most recent tweets.
Labeling Data Using Toloka
After scraping the tweets, we needed to assess the sentiment of each one. We categorized the sentiments as positive, negative, or neutral. But how could we efficiently label them?
For this purpose, we employed crowdsourcing through Toloka to gather our labels. We crafted a task where each participant received a set of tweets to label, as illustrated in the image below.
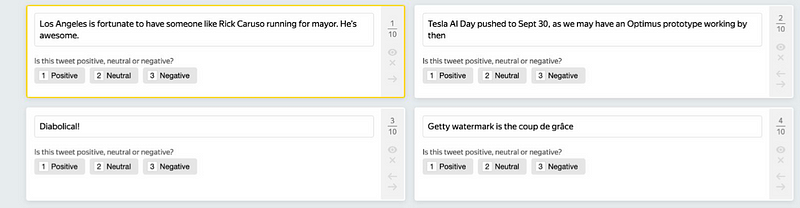
To ensure the quality of our labeling process, we established a comprehensive data labeling pipeline. Not everyone could label Elon Musk's tweets; only Tolokers who passed a language assessment, received training, and successfully completed an exam were eligible to participate. We also assigned the same labeling task to multiple workers, aggregating their results to enhance the reliability of our final labels.
Results and Insights
By the conclusion of our project, we had collected and labeled the sentiment of approximately thirty tweets. The majority of these were classified as neutral (18), with four negative and eleven positive tweets.
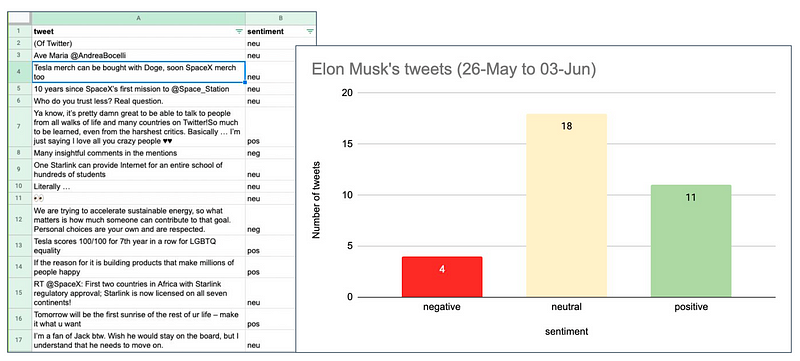
The main aim of this experiment was to showcase a streamlined and effective process that anyone can follow. For those interested in creating their own scraping and labeling project, we encourage you to check out our GitHub page, which contains the complete code for the pipeline described in this article. If you're uncertain about how to begin or have any questions, feel free to reach out to us in our online community.
Additional Resources
Learn how to extract and analyze Twitter data using Python in this engaging tutorial focused on Elon Musk's tweets.
This tutorial walks you through Twitter sentiment analysis using the Twitter API and OpenAI, specifically analyzing sentiments related to Elon Musk.