Maximize Revenue: Enhance Your Sales Funnel with ML in Python
Written on
Introduction
In today's economy, leads are vital to the success of many businesses. Particularly within the subscription-based model that is prevalent in startups, converting leads into paying customers is essential. A lead represents a potential buyer interested in your offerings.
When you generate a lead—whether through third-party services or your marketing campaigns—it typically includes:
- Contact information and name
- Attributes of the lead (demographic data, preferences, etc.)
- Source of the lead (e.g., Facebook Ads, website landing pages)
- Engagement metrics (time spent on the site, clicks, etc.)
- Referral details
The process of managing these leads, encompassing creation, qualification, and monetization, requires significant investment in time and resources from marketing and sales teams.
Lead Generation
Lead generation is the process of sparking interest in your products or services among potential customers. The aim is to translate that interest into sales. Numerous independent firms claim to offer the best lead generation services, but you can also initiate this process through your marketing campaigns. While unpaid channels like organic search results and referrals can generate leads, they are less common than paid advertising.
Lead Qualification
Lead qualification involves determining which prospects are most likely to make purchases. This phase is crucial in the sales funnel, which often accumulates numerous leads but converts only a fraction into buyers. Essentially, lead qualification ranks leads based on their conversion potential, allowing marketing and sales teams to prioritize efforts on the most promising prospects.
Lead Conversion
Lead conversion is the process of turning qualified leads into paying customers. This stage includes all marketing strategies aimed at encouraging leads to make purchases. The results from this final phase are often used to gauge the effectiveness of the overall marketing strategy.
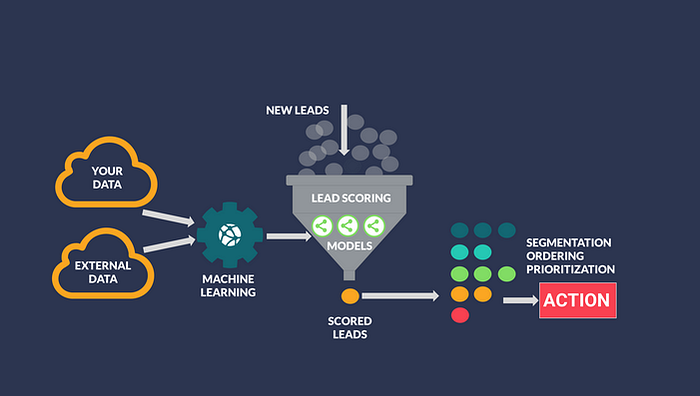
Imagine your team has generated numerous leads but lacks the resources to follow up with each one. Whether your business relies on a product-driven model with many freemium users, has an exceptional inbound lead funnel, or employs a robust door-to-door sales force, prioritizing leads is essential.
One way to improve the lead conversion process is to analyze historical data and identify the characteristics of leads that resulted in sales. For example, you might find that leads from a particular region convert at a high rate, or that visitors who spend a certain amount of time on your site are more likely to become customers. These insights can inform a lead scoring system, assigning scores to each lead based on their likelihood of conversion.
However, relying solely on business rules has its limitations. As your organization scales, the volume and types of data increase significantly, making a manual rule-based system inadequate. This is where machine learning comes into play.
By utilizing a machine learning perspective on the Lead Scoring System, you can train models using customer attributes, lead sources, referrals, and other accessible variables, aiming to predict whether a lead will convert.
To establish your target variable, most CRM systems, such as Salesforce and Zoho, can track the status of individual leads, which helps in defining the target variable.
Note: Be cautious about data leakage from your training dataset. For instance, if your CRM tracks referral fees paid for leads that convert, using that information in your training data can skew your results since it is only available post-conversion.
Tutorial / Implementation in Python
In this tutorial, we'll leverage PyCaret to train a machine learning model.
Introducing PyCaret
PyCaret is an open-source, low-code machine learning library in Python that simplifies the automation of machine learning workflows. To explore more about PyCaret, visit their GitHub page. You can install PyCaret via pip:
pip install pycaret
Dataset
For this tutorial, we'll use a Lead Conversion dataset sourced from Kaggle. This dataset includes over 9,000 leads, with features such as lead origin, source, time spent on the website, visits, and demographic data, along with a target column indicating conversion status (1 for conversion, 0 for no conversion).
# Import libraries
import pandas as pd
import numpy as np
# Read CSV data
data = pd.read_csv('Leads.csv')
data.head()
Exploratory Data Analysis
# Check data info
data.info()
Several columns in the dataset contain missing values. PyCaret will handle these automatically.
Intuitively, the time spent on the website, the activity score, and the source of the lead are crucial for predicting conversions. Let's visualize these relationships.
Leads coming from "Add Forms" are more likely to convert, regardless of the time spent on the website or their activity score. In contrast, leads from the landing page or API are more likely to convert if they have higher scores and spend more time on the site.
Initialize Setup
Before training machine learning models, we need to prepare the data using the setup function in PyCaret.
# Initialize setup
from pycaret.classification import *
s = setup(data, target='Converted', ignore_features=['Prospect ID', 'Lead Number'])
Model Training and Selection
Once data preparation is complete, we can begin training models using the compare_models function, which evaluates multiple algorithms based on various performance metrics through cross-validation.
# Compare all models
best_model = compare_models(sort='AUC')
The model yielding the best AUC score is the CatBoost Classifier, with an average 10-fold cross-validated AUC of 0.9864.
Confusion Matrix
The confusion matrix is a straightforward way to assess model performance by comparing predictions against actual results.
# Confusion Matrix
plot_model(best_model, plot='confusion_matrix')
In this matrix:
- True Positives: Predicted conversions that actually converted.
- True Negatives: Predicted non-conversions that did not convert.
- False Positives: Predicted conversions that did not convert.
- False Negatives: Predicted non-conversions that actually converted.
Summing all quadrants equals the total leads in the test set. In this case, we see 952 true positives, 70 false positives, 84 false negatives, and 1,667 true negatives.
Feature Importance
A feature importance plot helps interpret the model results, highlighting which features are significant in predicting lead conversions.
# Feature Importance
plot_model(best_model, plot='feature')
Applying the Model
Now that we have selected the best model, applying it to new leads to generate scores is straightforward.
# Create a copy of the data
data_new = data.copy()
data_new.drop('Converted', axis=1, inplace=True)
# Generate labels using predict_model
predict_model(best_model, data=data_new, raw_score=True)
The resulting dataset will include new columns for labels (1 = conversion, 0 = no conversion), along with probability scores for each class.
Thank you for following this tutorial! For more insights on data science, machine learning, and PyCaret, feel free to follow me on Medium, LinkedIn, and Twitter.
Chapter 1: Understanding Lead Management
Chapter 2: Machine Learning for Lead Scoring
This video covers how to optimize marketing spend using machine learning techniques in Python, providing insights on maximizing your marketing ROI.
In this video, we explore a Python project aimed at optimizing marketing campaigns through regression and correlation analysis, enhancing your understanding of data-driven decision-making.