Harnessing the TF_IDF Function in BigQuery for Text Analysis
Written on
Introduction to TF_IDF in BigQuery
In recent updates, Google has introduced several new functions that simplify the analysis of text data, including the TF_IDF function. This function is essential for evaluating the significance of a term in relation to a tokenized document.
For more insights on the new text functions in BigQuery, refer to my previous articles:
Google launches Text Analyze Function for BigQuery
How to extract terms from text and transform them into tokenized documents.
Google launches Bag of Words for BigQuery & BigQuery ML
How to conduct text analysis with ease.
Understanding the TF_IDF Function
The TF_IDF function operates using the term frequency-inverse document frequency algorithm, which assesses the importance of terms within a collection of tokenized documents. Essentially, it calculates the relevance of a term based on two metrics: how frequently the term appears in a document (term frequency) and how common the term is across a broader set of documents (inverse document frequency). This can be summarized as:
term frequency * inverse document frequency
This function is quite beneficial for text analysis in BigQuery, complementing other newly introduced functions like TEXT_ANALYZE and BAG_OF_WORDS.
Here’s a brief example to illustrate its usage:
WITH ExampleTable AS (
SELECT 1 AS id, [‘I’, ‘like’, ‘apple’, ‘apple’, ‘apple’, NULL] AS f UNION ALL
SELECT 2 AS id, [‘yum’, ‘yum’, ‘apple’, NULL] AS f UNION ALL
SELECT 3 AS id, [‘I’, ‘yum’, ‘apple’, NULL] AS f UNION ALL
SELECT 4 AS id, [‘you’, ‘like’, ‘apple’, ‘too’, NULL] AS f
)
SELECT id, TF_IDF(f, 10, 2) OVER() AS results
FROM ExampleTable
ORDER BY id;
This query yields the following output:
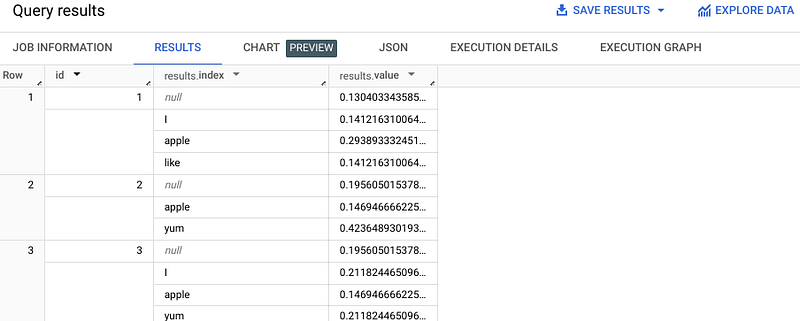
The query calculates the significance of up to 10 terms that appear at least twice in the tokenized documents. In this case, the parameters passed are positional: 10 indicates the maximum number of distinct tokens, while 2 denotes the frequency threshold.
The TF_IDF function is a valuable addition to BigQuery for those working with text data. Additionally, Google has rolled out other intriguing features that may also pique your interest:
Google launches Powerful Data Science Functions for BigQuery
Discover how to leverage more advanced mathematical functions in BigQuery.
Google launches an Update for BigQuery that can reduce Costs significantly
Learn how to utilize cached results from queries executed by other users within the same project.
Exploring Further with TF_IDF
This video, "How to Generate Text Embeddings, Sentence-Transformers, OpenAI Embeddings," delves into generating text embeddings, which can enhance your understanding of text analysis in BigQuery.
Analyzing Unstructured Text Data
In the video "Analyzing Unstructured Text Data," you will learn techniques for working with unstructured data, an essential aspect of data science.