Building a Data Lake with AWS: A Comprehensive Guide
Written on
Introduction to Data Lakes
In today's data-driven world, businesses of all sizes are accumulating vast amounts of information. Organizations collect data on their operations, clientele, competitors, and products, necessitating efficient storage, processing, and analysis methods.
Traditional systems like data warehouses and databases often fall short when handling the large volumes of data that modern enterprises encounter. Moreover, they lack the flexibility required for advanced analytics and machine learning, which have gained popularity in recent years.
This limitation of traditional data solutions has spurred the emergence of cloud storage and computing technologies, culminating in the innovative concept of data lakes. This guide will explain what data lakes are and how to establish one using AWS.
What Is a Data Lake?
The term "data lake" was coined by James Dixon in 2010, describing it as follows:
‘While a data mart is like a store of bottled water—cleaned and organized for easy access—the data lake is more akin to a natural body of water. It receives data from various sources and allows users to explore its depths or take samples.’
So, what does this imply for data storage and analysis?
In essence, data lakes are repositories capable of storing diverse data types, including structured (like tables), semi-structured (such as XML or JSON), and unstructured data (like text files). They can accommodate all forms of files, from images to videos and audio. This centralizes all company data, making it easily accessible for viewing and analysis.
Benefits of Utilizing AWS for Data Lakes
Today, numerous tools can facilitate the creation of data lakes, with AWS being a prominent choice. As a leader in cloud object storage and computing, AWS offers competitive solutions that are both affordable and efficient.
There are numerous advantages to leveraging AWS for your data lake. For starters, AWS S3 provides rapid, cost-effective, and user-friendly data retrieval. Additionally, AWS offers scalable analytical and machine learning services that are straightforward to implement.
These features make AWS a prime candidate for establishing a data lake. The introduction of AWS Lake Formation has further streamlined this process, enhancing ease of use.
Next, we will guide you through the process of setting up your inaugural data lake using this service.
Getting Started with AWS Lake Formation
To begin using AWS Lake Formation, you must first create an AWS account and set up an S3 bucket for your data. For this tutorial, you may utilize a Netflix dataset. Set up an S3 bucket called ‘yourname-datalake’ and upload the file named netflix_titles.csv into this bucket.
Once your data is safely stored in the S3 bucket, you can start the setup for AWS Lake Formation. Visit the AWS Lake Formation webpage and click on ‘Get started with AWS Lake Formation.’

Log in as a root user, where you will see a ‘Welcome to Lake Formation’ message.

When prompted, add yourself as an administrator. Upon completion, you should have access to the AWS Lake Formation Console, which resembles the screenshot below.

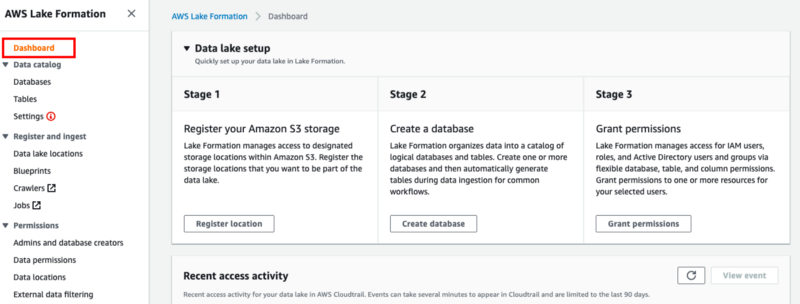
The AWS Lake Formation Console enables you to create your initial data lake. This article will walk you through the necessary steps, although AWS provides a comprehensive overview on the Dashboard tab within the console.
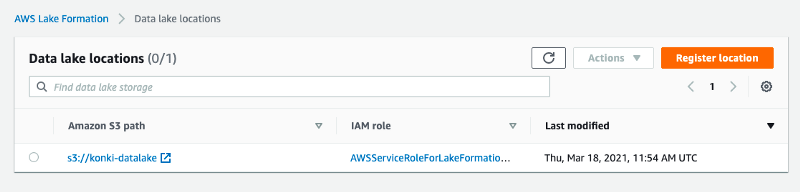
Begin by registering your S3 bucket. Click on ‘register location’ in Step 1, entering the name of your bucket where the dataset is uploaded. You can keep the default settings for the remaining options. You will see your registered location listed under Data Lake Locations.
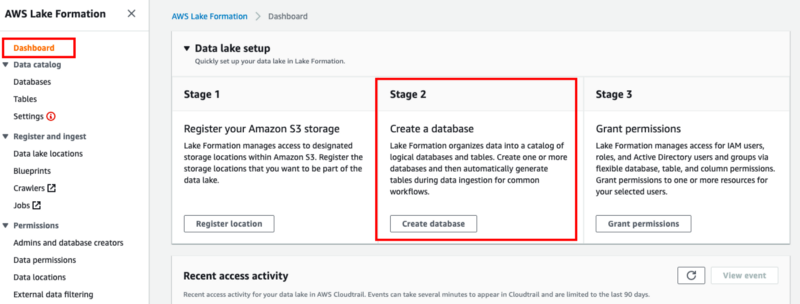
Return to the Dashboard and proceed to create a database as the next step.
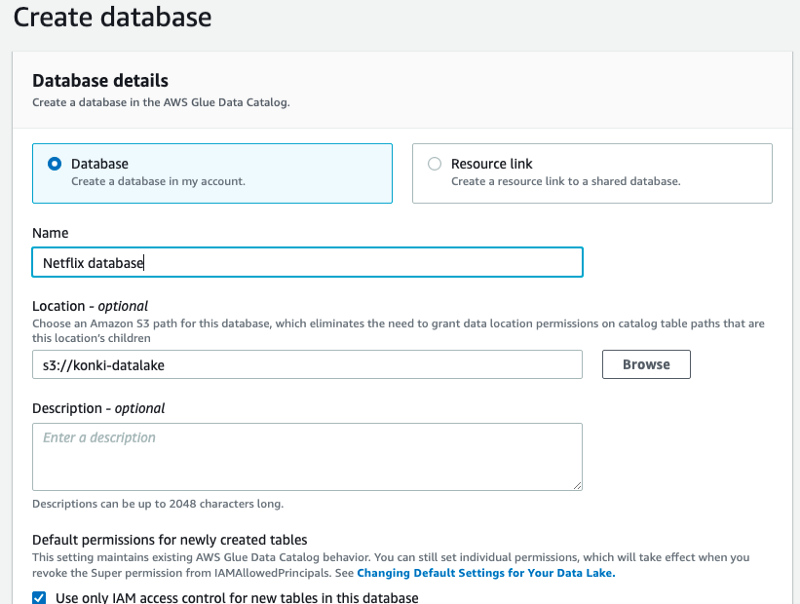
You can mimic my setup by naming your database ‘Netflix database’ and linking it to the S3 bucket that contains your netflix_titles.csv file.
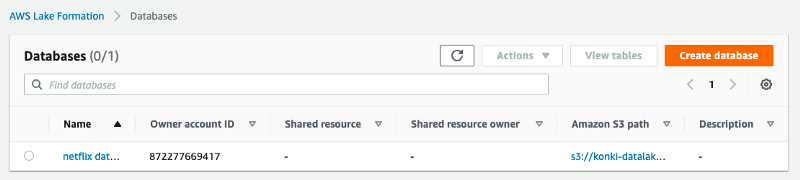
If you’ve followed these steps, your database should now be visible in the console.
Now, proceed to create a crawler by navigating to the crawler tab in the AWS Lake Formation Console.
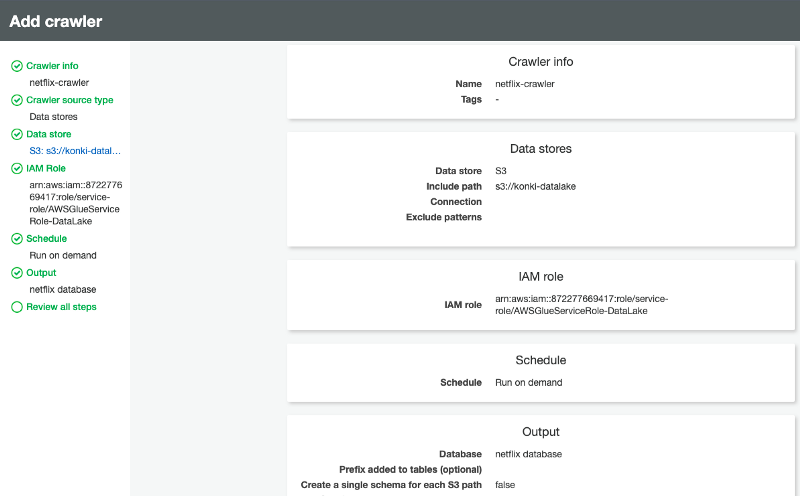
This action will lead you to the AWS Glue Console. Click on the ‘create crawler’ button and initiate the process by naming it (e.g., netflix-title-crawler). You can retain most of the default settings, following the structure shown in the screenshot below.
Ensure you input the crawler information according to the data setup previously established (S3 bucket path, database name, etc.). Note that in the fourth step, you will need to create an IAM Role for this service. I named mine AWSGlueServiceRole-DataLake, as shown in the screenshot below.
Once the setup is complete, your crawler will appear in the AWS Glue console. You can now execute the crawler. When the process finishes, the schema for your data and its metadata tables will be generated in the AWS Glue Data Catalog.
Wait for the crawler to finish and navigate to the Tables tab in the AWS Lake Formation Console.
You should now see that the table is filled with data from the netflix_titles.csv file. This database can now be utilized by other Amazon services such as Athena or Redshift.
Congratulations! You have successfully created your first data lake!
Summary
In this article, you explored the concept of data lakes and understood their significance in today's enterprises. You also learned how to set up your first data lake using AWS Lake Formation.
Although this tutorial was quite basic, it showcased how simple it is to establish data lakes with this new Amazon tool. This should encourage you to embark on your own data lake projects. If you aspire to become a data scientist, mastering data lakes is a crucial step towards a successful career. Be sure to delve deeper into data storage and processing techniques using data lakes.
Additional Resources
Explore the AWS re:Invent 2023 session on building and optimizing a data lake on Amazon S3. This presentation covers essential strategies and practices for effective data lake implementation.
Learn how to build a simple data lake on AWS utilizing AWS Glue, Amazon Athena, and S3. This tutorial provides a step-by-step approach to creating an efficient data lake.